我们都知道es是一个分布式的存储和检索系统,在存储的时候默认是根据每条记录的_id字段做路由分发的,这意味着es服务端是准确知道每个document分布在那个shard上的。
相对比于CURD上操作,search一个比较复杂的执行模式,因为我们不知道那些document会被匹配到,任何一个shard上都有可能,所以一个search请求必须查询一个索引或多个索引里面的所有shard才能完整的查询到我们想要的结果。
找到所有匹配的结果是查询的第一步,来自多个shard上的数据集在分页返回到客户端的之前会被合并到一个排序后的list列表,由于需要经过一步取top N的操作,所以search需要进过两个阶段才能完成,分别是query和fetch。
###(一)query(查询阶段)
当一个search请求发出的时候,这个query会被广播到索引里面的每一个shard(主shard或副本shard),每个shard会在本地执行查询请求后会生成一个命中文档的优先级队列。
这个队列是一个排序好的top N数据的列表,它的size等于from+size的和,也就是说如果你的from是10,size是10,那么这个队列的size就是20,所以这也是为什么深度分页不能用from+size这种方式,因为from越大,性能就越低。
es里面分布式search的查询流程如下:
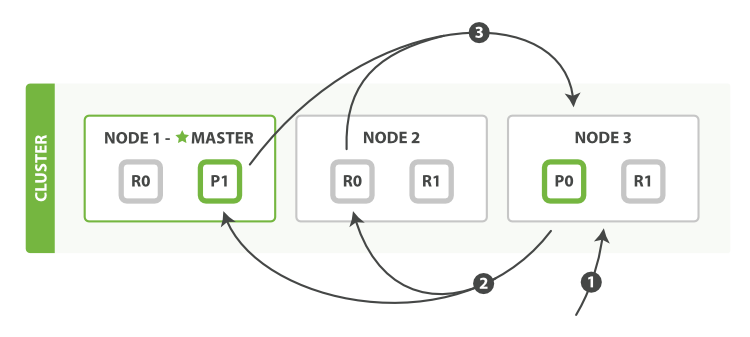
1,客户端发送一个search请求到Node 3上,然后Node 3会创建一个优先级队列它的大小=from+size
2,接着Node 3转发这个search请求到索引里面每一个主shard或者副本shard上,每个shard会在本地查询然后添加结果到本地的排序好的优先级队列里面。
3,每个shard返回docId和所有参与排序字段的值例如_score到优先级队列里面,然后再返回给coordinating节点也就是Node 3,然后Node 3负责将所有shard里面的数据给合并到一个全局的排序的列表。
上面提到一个术语叫coordinating node,这个节点是当search请求随机负载的发送到一个节点上,然后这个节点就会成为一个coordinating node,它的职责是广播search请求到所有相关的shard上,然后合并他们的响应结果到一个全局的排序列表中然后进行第二个fetch阶段,注意这个结果集仅仅包含docId和所有排序的字段值,search请求可以被主shard或者副本shard处理,这也是为什么我们说增加副本的个数就能增加搜索吞吐量的原因,coordinating节点将会通过round-robin的方式自动负载均衡。
###(二)fetch(读取阶段)
query阶段标识了那些文档满足了该次的search请求,但是我们仍然需要检索回document整条数据,这个阶段称为fetch
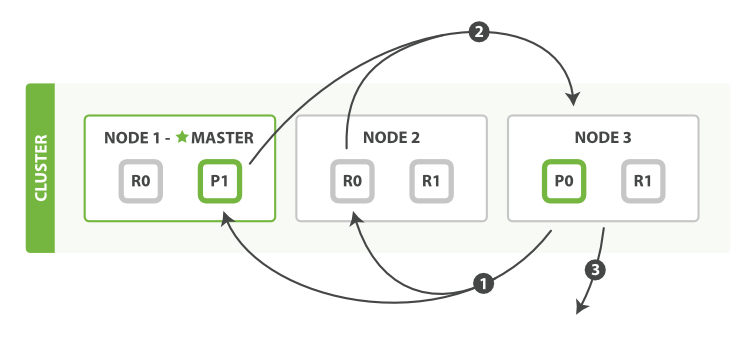
流程如下:
1,coordinating 节点标识了那些document需要被拉取出来,并发送一个批量的mutil get请求到相关的shard上
2,每个shard加载相关document,如果需要他们将会被返回到coordinating 节点上
3,一旦所有的document被拉取回来,coordinating节点将会返回结果集到客户端上。
这里需要注意,coordinating节点拉取的时候只拉取需要被拉取的数据,比如from=90,size=10,那么fetch只会读取需要被读取的10条数据,这10条数据可能在一个shard上,也可能在多个shard上所以 coordinating节点会构建一个multi-get请求并发送到每一个shard上,每个shard会根据需要从_source字段里面获取数据,一旦所有的数据返回,coordinating节点会组装数据进入单个response里面然后将其返回给最终的client。
总结:
本文介绍了es的分布式search的查询流程分为query和fetch两个阶段,在query阶段会从所有的shard上读取相关document的docId及相关的排序字段值,并最终在coordinating节点上收集所有的结果数进入一个全局的排序列表后,然后获取根据from+size指定page页的数据,获取这些docId后再构建一个multi-get请求发送相关的shard上从_source里面获取需要加载的数据,最终再返回给client端,至此整个search请求流程执行完毕,至于为什么es要通过两个阶段来完成一次search请求而不是一次搞定,欢迎大家在评论区讨论。